
Navigate the content tree like a pro with the GetAncestorOrSelf function
Navigating a content tree inside a CMS can be quite a challenge depending on performance and the functions that are available. I have been navigating trees for different CMS for a while and I noticed that some functions tends to come back often.
Let's say we have a multisite project. Any page can belong to any of the websites that are listed inside your EPiServer project. What do you do when you want to programatically know which website your page belongs to ? How do you generate a page that lists all the pages that are visible for the visitor without adding a direct reference to the "root" website page ?
You have to navigate the tree.
So I have been reading more about navigation inside EPiServer 11 and the functions available to navigate the content tree.
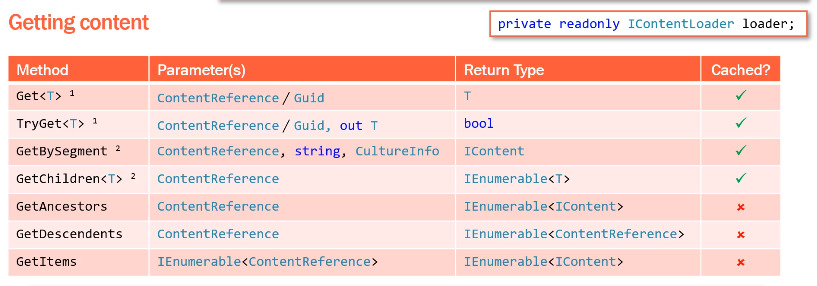
Based on the documentation I've seen, there are functions available inside IContentLoader that can be extremely useful to retrieve components and navigate inside the content tree:
- Get<T> - to retrieve any (unique) object based on a reference - preferred for performance as this function uses the cache and doesn't call the database.
- GetChildren<T> - used to retrieve children of a node in the content tree - another function using the cache, recommended by EPiServer for performance.
- TryGet<T> - same as Get<T> but returning a boolean, useful for scenarios when you are not sure if the casting is going to be successful.
- GetDescendents - Provide a list of all the "descendents" of a tree node all the way until we reach pages without children nodes. This function is not cached and hit the database every time you call it. As we want to navigate all the way up, this function is not the one we need at the moment.
- GetAncestors - Provide a list of all the "ancestors" of a tree node all the way until the "root" item. Wonderful ! Unfortunately this function doesn't use the cache and hit the database every time you call it noooooooooo 😭😭 - we were really close.
Information based on the EPiServer training for version 11. For previous versions please see the documentation.
So what do we want ? We want a function that helps us navigate the tree all the way up, if possible with an option to filter to retrieve the element that we want (root website page, in that scenario) with only cache functions.
For a little bit more clarity, this is what I mean by "root website page", my tree looks like that:
- Root
- Website1 - that's a root website page
- Website2 - that's another one
- Website3
- childPageOfWeb3
- DescendentOfWeb3
- Another descendent - I am currently here, I wanna get back to Website3, help me !🆘
- DescendentOfWeb3
- childPageOfWeb3
So I came up with a function to navigate the tree: an extension method for GetAncestorOrSelf(predicate) for IContentLoader.
As we are only using IContentLoader functions and we want this function to be as generic as possible, we decided to extend the IContentLoader capabilities with this helper function. We need a predicate because we wanna be able to provide a condition to filter the page that we are looking for.
How does it work ? From a specific node, we want to be able to loop all the way to the top while searching for the item that we are looking for.
The declaration will look like that:
public static IContent GetAncestorOrSelf(this IContentLoader contentLoader,
IContent content,
Func<IContent, bool> predicate)Why AncestorOrSelf ? I want to be able to locate the node I am searching for regardless of my position in the tree. I can be at the root or at the bottom, the condition will still be the same.
The rest is fairly straightforward, we loop all the way up and we run the condition to see if the condition works out:
public static IContent GetAncestorOrSelf(this IContentLoader contentLoader,
IContent content,
Func<IContent, bool> predicate,
int maxLevel = defaultMaxLevel)
{
if (content == null)
return null;
//pivot will be the variable that will be used to navigate up the content tree
var contentPivot = content;
//I prefer 'for loops' but while loops are just fine.
for (var i = 0; i < maxLevel; i++)
{
if (predicate.Invoke(contentPivot))
return contentPivot;
var parent = ContentReference.IsNullOrEmpty(contentPivot.ParentLink) ?
null :
contentLoader.Get<PageData>(contentPivot.ParentLink);
//if the parent is null - end of navigation
if (parent == null)
return null;
//we are still inside the tree, we continue to loop
contentPivot = parent;
}
//unlikely to happen but there to avoid stackoverflow exception. we return null
return null;
}As you can see, I am running a loop that will move from the child to the parent, run the condition & continue to loop if I don't find anything.
At that point you surely have spotted the Get<> function - mandatory cache function to retrieve information about the parent as ParentLink is only a reference and we need the full parent object.
Why am I using a for() loop instead of a while() ? I do not like the while keyword.
In short, those loops are a proper trap for developers to generate infinite loops, stackoverflow exceptions and other nightmares. Forgetting about a 'break' clause shouldn't be that fatal of a mistake. From a performance POV I want to be able to "control" how long my loop will run, this is why it is possible to add a maxLevel property to guarantee my loop will stop regardless.
Let's get back to my problem, I want to locate Website3 programmatically without decorating my object with interfaces or decorators. My condition will be:
The node I am looking for is the one of my ancestors and its parent is the EPiServer 'root' node - the root of all websites.
How does it translate in code ? Something like this:
(content) =>
{
var parent = ContentReference.IsNullOrEmpty(content.ParentLink) ?
null :
contentLoader.Get<PageData>(content.ParentLink);
if (!(parent is PageData typedParentPivot))
return false;
return typedParentPivot.PageTypeName == "SysRoot";
});My condition is:
I will load the parent node information using Get<> and check that the parent PageTypeName = SysRoot, the default type name for the root node in EPiServer CMS.
And it works ! Hoorayyyy 🥳🥳
But we have to stop the party. There's an issue with that condition. I am calling Get<>(parentLink) twice for each loop 😱😱 so much for performance !
How do we solve it ? That's why we need a second version of GetAncestorOrSelf() with the parent inside the predicate:
public static IContent GetAncestorOrSelf(this IContentLoader contentLoader,
IContent content,
Func<IContent, IContent, bool> predicate,
int maxLevel = defaultMaxLevel)
{
if (content == null)
return null;
//pivot will be the variable that will be used to navigate up the content tree
var contentPivot = content;
//please do not use 'while' loops
for (var i = 0; i < maxLevel; i++)
{
var parent = ContentReference.IsNullOrEmpty(contentPivot.ParentLink) ?
null :
contentLoader.Get<PageData>(contentPivot.ParentLink);
//we can allow the predicate to work even with a null parent
if (predicate.Invoke(contentPivot, parent))
return contentPivot;
//if the parent is null - end of navigation
if (parent == null)
return null;
//we are still inside the tree, we continue to loop
contentPivot = parent;
}
//unlikely to happen but there to avoid stackoverflow exception. we return null
return null;
}By including the parent inside the predicate, we don't need to call Get<> for the parent twice as it is already available !
We can finally finish with our helper function to retrive the node tha we were looking for:
public static IContent GetRootSite(this IContentLoader contentLoader, IContent content)
{
//predicate here is: parent must be 'sysroot'
var rootSite = contentLoader.GetAncestorOrSelf(content,
(pivot, parentPivot) =>
{
if (!(parentPivot is PageData typedParentPivot))
return false;
return typedParentPivot.PageTypeName == "SysRoot";
});
return rootSite;
}And that's a wrap ! We have our helper function to retrieve the node we were looking for and in the process we got a helper function GetAncestorOrSelf with 2 method signatures. Happy days !
And because we are feeling generous, why not include a GetAncestor(predicate) function as well ? It's quite easy with GetAncestorOrSelf() :
///for this function we move to the first parent then call GetAncestorOrSelf
public static IContent GetAncestor(this IContentLoader contentLoader,
IContent content,
Func<IContent, bool> predicate,
int maxLevel = defaultMaxLevel)
{
if (content == null)
return null;
var parent = ContentReference.IsNullOrEmpty(content.ParentLink) ?
null :
contentLoader.Get<PageData>(content.ParentLink);
//pivot will be the variable that will be used to navigate up the content tree
//we start with the parent
var contentPivot = parent;
return GetAncestorOrSelf(contentLoader, contentPivot, predicate, maxLevel);
}Now that we have those functions ready, the possibilities to filter are limitless, we could search for:
- The first ancestor / parent / current page with a specific page type
- The first ancestor that was published after a specific date
- The first ancestor that has 5 child nodes
- The first ancestor with a specific interface
The sky is the limit 😊 I hope this article was helpful to you. Stay safe
Really useful, thanks Giuliano!
Usually when you are traversing the tree you are loading out common items such as the name, URL and such and often based on the design of your content models. So when I do this I would usually
This has the benefit of caching the model so semi expensive calls to area such as the UrlResolver aren't handled move than once.
Just an alternate approach but I try to cache as much as possible against the ISynchronizedObjectInstanceCache for super high performance
Nice write up Giuliano.....also nice alternative @Scott Reed.
Excellent idea @Scott Reed