
CI/CD using Episerver DXP Deployment API and multi-stage YAML pipelines - Part 1
This post is the first in a series to share my recent experience in setting up CI/CD pipelines using the Deployment API and YAML pipelines. The end goal is to have a CI/CD process that can be quickly setup for any new project. The focus of this post will be a branching and release strategy which is key in supporting a robust DevOps process.
Preface
Before the release of the Deployment API, Episerver DXP only supported a linear deployment model whereby you could only deploy to Integration and then promote the package through the environments using the PaaS Portal. This created challenges for managing concurrent development of consecutive releases or to deploy an urgent hotfix to Production. The Deployment API, using the code package approach, has made it possible to fully integrate and manage CI/CD pipelines in Azure DevOps.
Having used Azure Pipelines Classic UI to setup CI and Release pipelines, I'm continually looking for DRY ways to speed up the setup. Azure Pipelines now has support for multi-stage YAML pipelines so you can configure pipelines to do CI and CD tasks in one YAML file. Compared to Classic UI features, YAML still has some catching up to do but given the benefits of version control and portability between projects, using YAML is an excellent way to standardise CI and CD pipelines across your projects.
For branching strategy, after using GitFlow for a number of years, I wanted to try something simpler without the overhead of branch management and merge hell. I recently discovered the Release Flow model and was amazed by its simplicity.
What is Release Flow
Release Flow is Microsoft's DevOps workflow to build and deploy all their products. The interesting bit is that they apply this methodology using Azure DevOps to deploy changes to Azure DevOps.
It uses a trunk-based branching strategy for development and releases. This is a lesser-known branching model that is becoming more prevalent and is practiced by large organisations like Google and Facebook.
Branching strategy
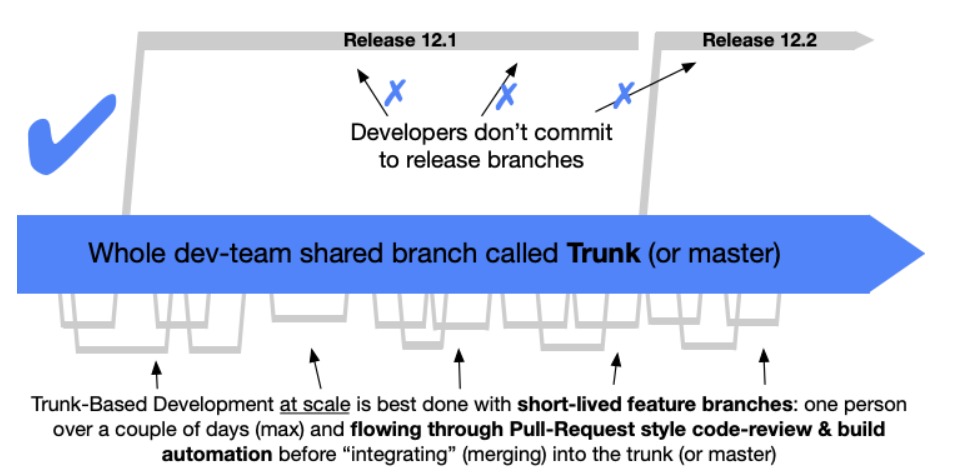
There is a link at the end of the post if you want to learn more about concepts of Trunk based development (TBD)
Development
The key concept of this branching model is there is only one main branch, master (the trunk) providing a single consistent view of the codebase. All development work, either to implement a feature or fix bugs requires developers to create short-lived feature branches off master. Typically these feature branches will only last 1-2 days.
Feature toggles (flags) can be used in avoiding long-lived feature branches, to control the release of incomplete or new features. The basic idea is to have a config file with flags or you can store the flags in CMS.
Merge into master branch is done via pull requests which facilitates peer reviews and ensures branch policies are satisfied before the pull request can be completed. Merging small changes as often as possible to master is encouraged for a quicker code review process and to get early feedback from other developers.
When the feature branch is merged into master, this will trigger the CI/CD YAML pipeline to build, run any unit tests, package, and deploy to the Integration environment. Functional and end to end tests are done on the Integration environment, any bugs are subsequently fixed and merged to master.
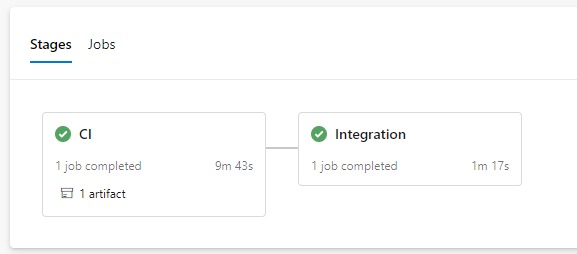
Release
At the end of a sprint or a few days before a planned monthly release, developers create a new release branch from master. It is important to have a consistent naming convention for release branches e.g. release/<major.minor>. This version number can then be used by the release pipeline to tag the release and identify the version deployed to an environment in Azure DevOps (more on this in the next post).
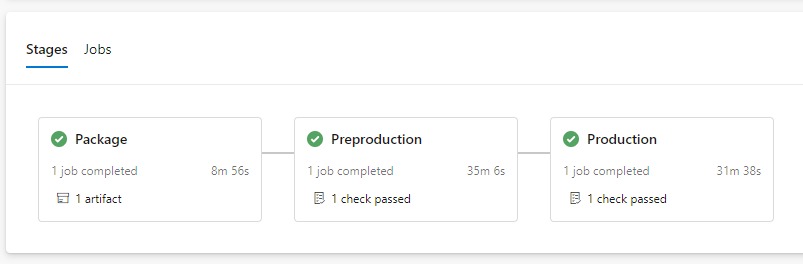
When the release branch is pushed to the server, this will trigger the Release YAML pipeline to build, create a code (Nuget) package, and upload it to Episerver DXP ready for staged deployments to Preproduction and Production (upon approval).
Any bugs discovered in Preproduction should be fixed off master and cherry-picked/merged onto the release branch. This branching model forbids developers committing to release branches and merging them back into master
As a tidy up activity, release branches are deleted once the release is no longer in Production.
Hotfixes
To fix a production bug, the normal development workflow is followed i.e. create a branch off master and merge into master via pull request. Once completed, the fix can then be cherry-picked/merged into the release branch. Azure DevOps provides an option on completed pull requests to cherry-pick it to release branch(es) without needing to pull the release branch locally. This will open a new pull request targetting the selected release branch.
Following this process guarantees the fix is in master first and won't be regressed in later releases. If you fix in the release branch first, there is a risk of regression if you forget to merge it into master in the chaos of releasing the fix to Production.
In case the bug can't be reproduced on master then you have no choice but to do it the other way around i.e. fix on the release branch and merge back to master. This should only be used as a fallback option.
The Release YAML pipeline can also be used to deploy the hotfix directly to Production if there is an urgent outage to resolve (more on this in the next post).
Wrap up
Release Flow model may not be for every development team/project and developers familiar with GitFlow will find it different but I found its simplicity works well with deploying to Episerver DXP using the Deployment API. The other plus is less merge pain. I'm keen to see how the model scales after using it on a few projects.
In the next post I'll be doing a deep dive into the reusable CI/CD YAML pipelines.
References
https://docs.microsoft.com/en-us/azure/devops/learn/devops-at-microsoft/release-flow
https://trunkbaseddevelopment.com/
Comments